.
The sequencing was conducted by the
whole-genome shotgun strategy using southern
inbred strain, Hd-rR. The genome was assembled from 13.8 million reads, obtained from the whole genome shotgun
plasmid,
fosmid, and
bacterial artificial chromosome (BAC) libraries. The total size of the assembled contigs was 700.4 megabases (Mb). 50% of nucleotides are covered in scaffolds (or contigs) of length 1.41Mb (9.8 kilobases) that are called N50 values. This contiguity is sufficient to characterize the genomic structures of genes.
Four versions of the medaka genome sequence data named 200406, 200506, version 0.9, and version 1.0 have been released to the public to provide users with timely information. The former two versions had shorter scaffolds that were not anchored on the medaka chromosomes because they were built in 2004 and 2005, before genetics markers were available. Versions 0.9 and 1.0 created in 2006, when comprehensive genetic markers were available, so that about 90% of their scaffolds and ultracontigs were located on the twenty-four medaka chromosomes. Versions 0.9 and 1.0 were built from the identical contigs and scaffolds, but the assembly of version 1.0 is longer than that of version 0.9 because more genetic markers could be used to generate version 1.0. Version 0.9 is left open to the public because most of the data analysis in the medaka genome paper published in
Nature (2007) was based on version 0.9.
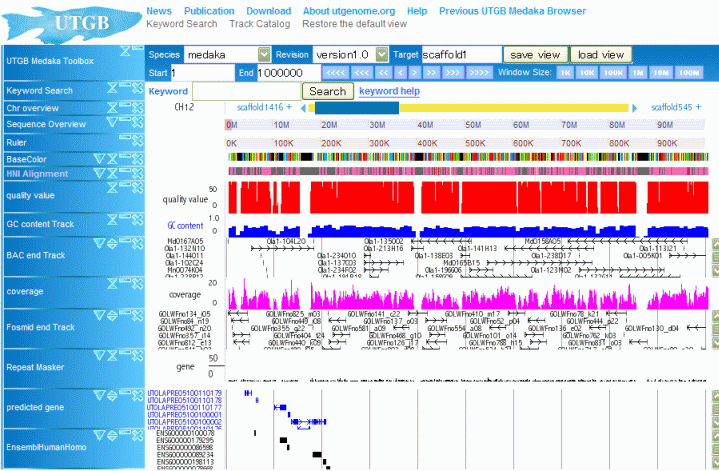
The University of Tokyo Medaka Genome Browser (UTGB Medaka) a web-based genome database browser, which provides various information related to medaka genomes, including assembly sequences, genes, clones, homologus genome sequences to other species, etc.